Codetown
Codetown ::: a software developer's community
What's the difference between Grid computing and Cloud Computing
I don't clearly catch the difference betwenn these two concept. Someone told me that the essential différence is that the cloud computing give you a large space of storage and the grig give more advantages than storage, we can profit to much power with this last.
Does any one know more clearly these two concept; and tell us?
Views: 253
Replies to This Discussion
-
Permalink Reply by Thomas Michaud on
-
I don't claim to be the expert, but the difference is (I think) in use.
Grid represents a scalable framework. You write your algorithm and your code and use as much computing power as you wallet can afford. (Useful as some work can be highly parallelizable) .
Cloud computing offers storage (true) but it's also represents the applications as well. Ideally with cloud computing, you don't need to have certain applications on your desktop - as long as you can hit the cloud, you can get, update, and use your data.
-
-
Permalink Reply by Hervé-greg MOKWABO on
-
Thanks thomas;
What I got :
Grid - much computing power and can be highly parallelizable
Cloud - Storage and dont need to have certain applications on your desktop ( that's just like server application?)
Someone can tell us more?
-
-
Permalink Reply by Bradlee Sargent on
-
I think if you look at the history, you will understand some difference.
In my own experience, the grid began with Oracle using it as a type of metadatabase, which would point to multiple databases residing on different but uniform hardware systems. So if a company had multiple unix boxes and needed to increase the size of their database, instead of purchasing additional hardware they could implement the grid database and combine their multiple unix servers into one database resource.
Cloud is much more in terms of it offering not only a database, but also an entire server including the operating system.
The cloud exposes an operating system, whereas a grid exposes a database.
But I am no buzz word expert so I might be wrong.
-
-
-
I just talked to a buddy about this, essentially the Oracle Grid product is differant because it runs the DB in memory. So access times are a lot quicker. I don't think it is really a matter of Vs. so much as Grid computing is a way to handle db transactions in a faster way.
He said their grid servers had something like 72gbs of ram. Freaking crazy
-
-
-
Please Bradley, wha do you think about Jackie's reaction?
-
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Cloudflare Processes 10M+ Daily Insights with New Security Overview Dashboard
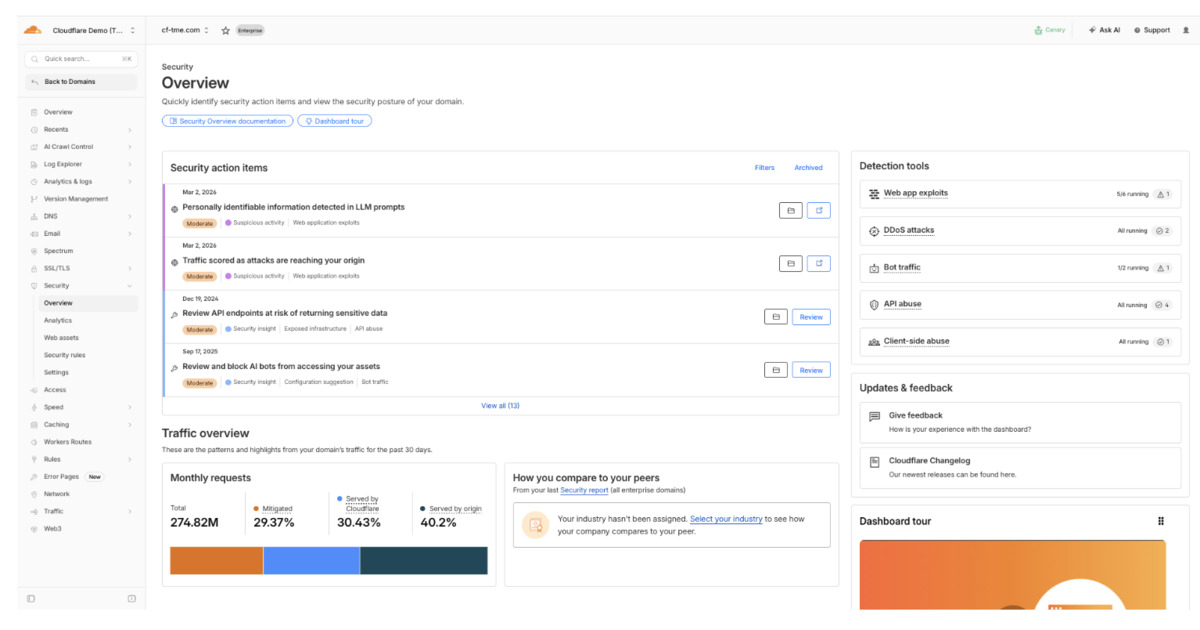
Cloudflare has launched a Security Overview dashboard that consolidates security signals into prioritized action items. It surfaces millions of daily insights, helping teams identify and remediate critical risks faster. Built on distributed checkers and real-time event processing, it integrates analytics workflows to reduce investigation overhead and improve response efficiency.
By Leela KumiliPresentation: The Human Scalability Problem: Why Your Teams Don’t Scale Like Your Code

Charlotte de Jong Schouwenburg discusses the "human bottlenecks" of hyper-growth. While systems scale, human cooperation often breaks down due to communication overload and lost context. She shares proven tools for behavioral scalability - including communication architecture and "engineering trust" - to help leaders maintain high-performing, autonomous teams without sacrificing speed or culture.
By Charlotte de Jong SchouwenburgArticle: From Batch to Micro-Batch Streaming: Lessons Learned the Hard Way in a Delta Index Pipeline

This article describes how a production delta-index pipeline migrated from scheduled batch to micro-batch Spark Structured Streaming. It covers why record-level streaming was rejected, how partition-based watermarks replaced fragile S3 completion markers, overlap-window correctness, and restart-as-design strategies for better predictability in object-store–based ingestion systems.
By Parveen SainiPodcast: Roq: Leveraging Quarkus to Build Static Sites at the Speed of Go
Andy Damevin, a developer who worked on Quarkus for almost a decade, talks about Roq. A project that started as an experiment to try to see if it’s possible to build a static web site generator on top of quarkus. He touches on the rationale for choosing Java and Quarkus, how to migrate to Roq, and the platform's future.
By Andy DamevinDoorDash Used Copilot to Convert Its XCTest-Based iOS Test Suite to Swift Testing

Using Copilot along with strong reliability safeguards, DoorDash migrated their iOS XCTest-based test suite to Swift Testing, thus modernizing a large test suite quickly, safely, and with measurable performance gains, says DoorDash engineer Matheus Gois.
By Sergio De SimoneSwitch to the Mobile Optimized View
© 2026 Created by Michael Levin.
Powered by
![]()