Codetown
Codetown ::: a software developer's community
What's the difference between Grid computing and Cloud Computing
I don't clearly catch the difference betwenn these two concept. Someone told me that the essential différence is that the cloud computing give you a large space of storage and the grig give more advantages than storage, we can profit to much power with this last.
Does any one know more clearly these two concept; and tell us?
Views: 259
Replies to This Discussion
-
Permalink Reply by Thomas Michaud on
-
I don't claim to be the expert, but the difference is (I think) in use.
Grid represents a scalable framework. You write your algorithm and your code and use as much computing power as you wallet can afford. (Useful as some work can be highly parallelizable) .
Cloud computing offers storage (true) but it's also represents the applications as well. Ideally with cloud computing, you don't need to have certain applications on your desktop - as long as you can hit the cloud, you can get, update, and use your data.
-
-
Permalink Reply by Hervé-greg MOKWABO on
-
Thanks thomas;
What I got :
Grid - much computing power and can be highly parallelizable
Cloud - Storage and dont need to have certain applications on your desktop ( that's just like server application?)
Someone can tell us more?
-
-
Permalink Reply by Bradlee Sargent on
-
I think if you look at the history, you will understand some difference.
In my own experience, the grid began with Oracle using it as a type of metadatabase, which would point to multiple databases residing on different but uniform hardware systems. So if a company had multiple unix boxes and needed to increase the size of their database, instead of purchasing additional hardware they could implement the grid database and combine their multiple unix servers into one database resource.
Cloud is much more in terms of it offering not only a database, but also an entire server including the operating system.
The cloud exposes an operating system, whereas a grid exposes a database.
But I am no buzz word expert so I might be wrong.
-
-
-
I just talked to a buddy about this, essentially the Oracle Grid product is differant because it runs the DB in memory. So access times are a lot quicker. I don't think it is really a matter of Vs. so much as Grid computing is a way to handle db transactions in a faster way.
He said their grid servers had something like 72gbs of ram. Freaking crazy
-
-
-
Please Bradley, wha do you think about Jackie's reaction?
-
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Cycle Introduces EU Control Plane as Sovereignty Debate Continues
Cycle recently introduced a separate EU-based control plane, allowing European customers to keep platform management data and telemetry within Europe. The new offering is designed to improve compliance, operational isolation, and responsiveness for European organizations.
By Renato LosioCloudflare Details Unified Data Platform Where Billing Workloads Account for 53% of Queries
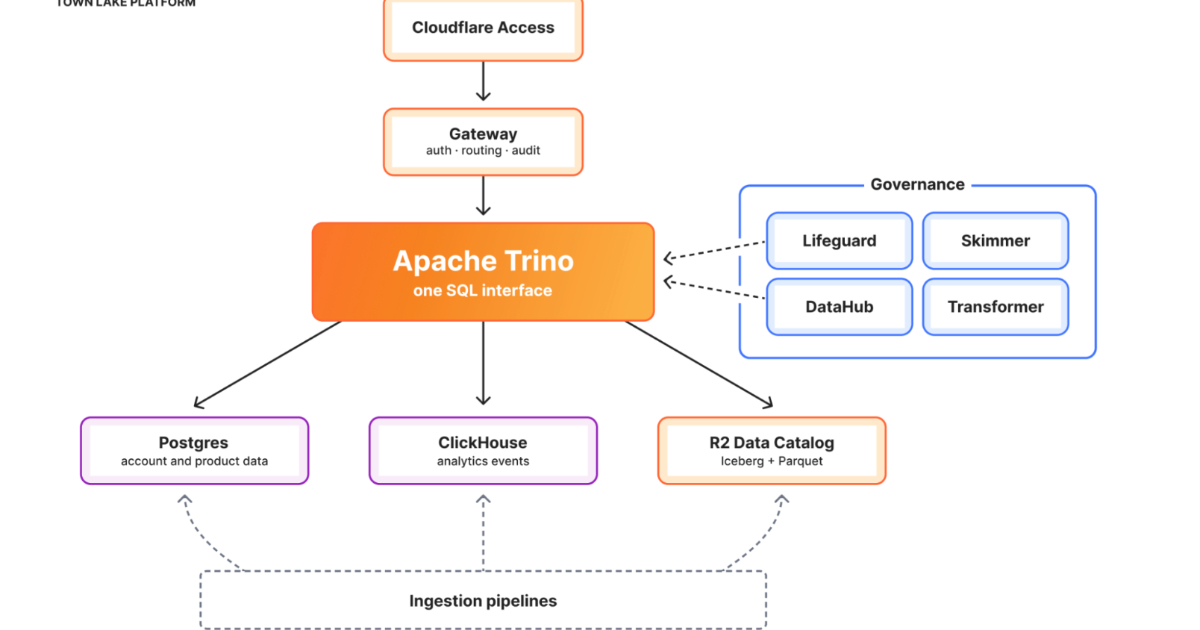
Cloudflare details Town Lake, an internal unified data platform, and Skipper, an AI analytics agent unifying access to operational, billing, security, and business data. The platform processed ~91K billing queries, with billing forming majority usage. Built on a lakehouse architecture using Trino, Iceberg, R2, and DataHub, it enables governed cross-system analytics and natural language access.
By Leela KumiliHardwood Promises High-Speed JVM Apache Parquet Processing with Zero Mandatory Dependencies
Hardwood, the project Gunnar Morling kick-started to improve the handling of Parquet files in Java, reached version 1. Its multi-threaded approach and zero mandatory external dependencies promise a simpler, optimal alternative to the Apache Parquet Java implementation. For now, the library provides a reading via API and a CLI for visualisation; writing support is expected in the upcoming versions.
By Olimpiu PopOpenTelemetry Graduates to CNCF's Highest Maturity Level

The Cloud Native Computing Foundation (CNCF) has announced the graduation of OpenTelemetry, elevating the project to the foundation's highest level of maturity and formally recognizing it as production-ready for enterprise use.
By Craig RisiMini book: Agentic AI Architecture

In this eMag, we try to establish agentic AI architecture as a new type of software architecture that will likely dominate the industry for years to come. The articles, written by industry experts, cover various elements and aspects of agentic AI architecture. We aim to present the latest trends and developments shaping the new type of architecture as it enters the mainstream.
By InfoQ
© 2026 Created by Michael Levin.
Powered by
![]()