Codetown
Codetown ::: a software developer's community
The advantages of a RESTfull web-based API
I need to get a better handle on the advantages of a RESTful web-based API. People tell me they scale better than other methods, but I don't see how they reduce database access or have any other feature that helps handle large amounts of traffic. The RESTful naming convention certainly helps keep them organized and 'orthoganal' , so if you DO have a web API it makes sense to keep it RESTful, but my main question is - if you don't plan on your database being accessed from anything other that the server/client apps you write yourself, is their any advantage?
Views: 456
Replies to This Discussion
-
Permalink Reply by George on
-
Your question about “the advantages of a RESTful web-based API” leads me to ask the following: advantage over what other type of API? Most people compare and contrast REST with XML and argue the advantage of one over the other.
The REST payload is much smaller than most other APIs especially XML over SOAP. REST is well suited for hand held devices and other devices that have a low speed connection. The hand held may communicate with a server using REST to deliver the payload to from the hand held to the server. From that point on, the server may communicate with a target system such as a database using an alternate protocol or method.
REST and its popular JSON format is more dynamic than XML and less rigid than XML.
XML over SOAP continues to be widely used for integration between enterprise packaged applications. Most enterprise packaged application include, out of the box, an XML over SOAP API for the purpose of integrating that application with other applications in the enterprise. I do see newer packaged applications now including both flavors, REST and XML. But for sure enterprise packaged application mostly provide an XML over SOAP API.
I believe the learning curve for SOAP is very steep because it contains many different w3c specifications often referred to as WS-* included in the SOAP spec.
One size does not fit all. I may have no choice but to use XML because that’s what the enterprise packaged application includes out of the box. On the other hand, if it’s a mobile hand held device, a light weight protocol such a REST is superior.
Applications today (and over the last 20 years) are multi-tier. Your client app may communicate with a server via some protocol such as REST or XML. And the server may then communicate to a database via JDBC. I worked on a system where a hand held communicates with an API gateway hosted in the DMZ using REST. The Gateway communicates with an ESB middleware server via XML, and the ESB then communicates to a packaged application via yet another protocol. With this application, security was most important. And for scalability, the back-end server must be sized to handle the load.
I hope this helps.
-
Permalink Reply by Fred Sells on
-
I find RESTful apps to be easier to maintain and easier to debug when compared to a framework that uses some templating language like JSP or Django. It is much easier if you use some library like jQuery or Angular JS, although these come with a learning curve ... but once you have moderate skill it is just more fun to design applications. An frankly in an industry that can be "de-humanizing" it is important to enjoy and take pride in the work you create.
Another handy trick is that you can read json or xml files while doing initial development rather than having to simultaneously build the server. Then when the client is sufficiently complete, these data files server as a "contract" to define what the server needs to provide.
I'm currently converting an application from Flash to AngularJS and I have to admit, the learning curve is much steeper than for more conventional librarys like jQuery. But the resulting code elegance is worth it if you have the time to learn.
Of course that's just my opinion, I could be wrong :)
Fred.
-
Permalink Reply by Pavel Gilo on
-
Like some already have said. Its a simpler implementation that is typically simpler to maintain and has a smaller payload, Typically in JSON format. I think the more important question is what are the disadvantages.
But if your building a simpler server/client app, there may not be any advantage to implementing REST, unless your taking the SPA approach.
I guess it all boils down to what you want to accomplish.
-
-
Actually, REST is not an API and there is no such thing as "RESP API", although for some reason we use SOAP, XML-RPC and REST in our vocabulary as if they were interchangeable forms of API design and they are not.
REST is about Architectural Design and Resource Representation and it's a far much deeper concept than "API", which requires careful reading and thoughtful understanding of the PhD dissertation that coined the term, and all related IETF RFCs. So to really discuss this topic it would require that all of the participants in the discussion be fully familiar with the aforementioned dissertation, and of course a deep technical understanding of the original design goals of the original HTTP 1.0 and the evolution of this protocol leading up to the recent 2.0 proposal, by reading __and understanding__ all the related RFCs.
For one thing a REST design can represent resources in any form, whether it's HTML, XML, JSON or a JPEG file and in general any representation that makes sense to the User Agent per the suggestions of the Accept and Content-Type headers. So representation is one aspect whilst the question actually relates to scalability and database access, which is wrongly assuming that all resources will be pulled from a database, and that is the __least__ ideal case.
The scalability of REST comes primarily from taking advantage of caching, but there are many other important reasons (related to the CAP theorem). This means that the representation of the resource must include all the required information to understand it (including it's "state" hence the term "REpresentational State Transfer". This means that any network component must not need to look beyond the resource metadata (basically the HTTP verb and headers) to decide what to do with it, hence it's faster and more secure just by definition. This is BTW the main draw back and main weakness to using SOAP, XML-RPC or other tunnelling-style protocols over HTTP, which would require peeking into the content of the package and understanding the tunnelled protocol (e.g. SOAP) to understand the intention of the request. Which brings us to the most important misunderstanding about HTTP: is a TRANSFER and NOT a transport protocol. Hence SOAP and XML-RPC are by definition trojan horses tunnelled over HTTP. They are extremely unreliable for anything beyond the scope of LAN and should be banned from use in large-scale implementations or for anything that should be considered Internet-scale.
Back to the original question, perhaps the best way to __begin__ to understand this is by example:
Suppose you have a typical business system which handles inventory and sales. In any such system you will find that there are many more READ requests than WRITE ones in a ration that usually exceeds 10:1. If you map this to your UI it is likely that you will have about 10 GETs for every one POST, PUT or DELETE. Furthermore, viewed from the resource modelling level, most if this data is either non-mutable or slowly mutable which could perfectly allow for caching.
Take an inventory item for example, you may think that inventory level is critical but in reality most business models can deal with a an old value, but it will depend on the nature of the item. For example, if you are selling items and unless the lead time is excessive, you are not going to stop a sale because you don't have sufficient inventory, business will generally prefer to sell and then handle a back-order process, so things like negative inventory quantities are quite common. On the other hand a spare part in a nuclear facility requires exact and real-time access to the inventory level of this part (known as safety stock) and this holds true for most reliability-centred operations.
So what is the resource? In this case it is usually the part record ro simply put un REST terms "the part" or the "item". How cacheable is it? it depends. Some parts will be more cacheable than others and some may be non-cacheable, forcing a request to the database to obtain the real-time value. This resource-cache definition maps directly to HTTP GET and caching directives, in other words, both the lead time and criticality of the part will determine for how long the network components (including the user agent) may cache each item resource. This means that only the first GET /part/{id} will actually fetch the info from the DB and construct a representation in some format that is cacheable by any component of the network. For example a JSON representation that is stored and propagated in an HTTP-based noSql system such as MongoDB. In other words, the resource is stored in a relational DB but after the first get it gets cached (for a given time frame according to the HTTP caching directives which are determined by the items lead time and criticality as stated above). From then on, any network component and/or user agent requiring this resource could obtain a local copy, whether in it's own cache (e.g. the browser's cache) or from some near-by network component who also holds a copy (e.g. a caching network proxy).
As another example take an invoice. An invoice is stored in the RDBMS as a master-detail record (a.k.a. one to many relationship). This means that EVERY TIME I need to fetch the invoice I must first query for the header data, get some other related data (e.g. customer info, billing and shipping addresses, etc.) and then query for each individual invoice-line to be able to construct the "invoice resource" which is ultimately what the consumer wants, and this may need to bring in some other related data as well (usually in the form a complex join or sub-query) . In other words RDBMS is very effective at storing complex and relational data but it's really ineffective at extracting, constructing and distributing this data across multiple nodes for millions of GET requests. And the worst part of this is that most system designers and programmers don't even realize that in the case of the invoice this data is NON MUTABLE, EVER. This means, that once stored in the RDBMS by the invoicing code, there could just be a simple trigger that de-normalizes this data and serializes it to a JSON structure that is easily distributable across thousands of nodes and NEVER have to go to the database again to retrieve this information.
This means that once the invoice resource is created it can have a cache forever header so not only user agents do not have to wait until the request makes it all the way down to the RDBMS and have to construct the de-normalized object each time. This resource will be ultimately cached in the Browser's cache and NEVER again (unless user cleans their cache) need to even consult the network to obtain a copy of it.
Ans this is just the tip of the iceberg but the point is that REST is a complete architectural design and you must be familiar with all the levels involved (e.g. network, user agents, HTTP), and not only talk about API design.
So basically to answer your question: in a typical RESTful design, most POST, PUT, DELETE will follow a different path than GET. In other words, non-idempotent (or "write") methods will usually route through some code and then to a RDBMS while most idempotent methods (or "reads") will route to near and cached resource storage (even local as is the case of a Browser), therefore dealing with the CAP theorem. Basically, a real RESTful system must be carefully designed to take advantage of caching and eventual consistency and be modelled in resources not API.
-
Permalink Reply by Kevin Neelands on
-
Alejandro IMass said:Actually, REST is not an API and there is no such thing as "RESP API", although for some reason we use SOAP, XML-RPC and REST in our vocabulary as if they were interchangeable forms of API design and they are not.
REST is about Architectural Design and Resource Representation and it's a far much deeper concept than "API", which requires careful reading and thoughtful understanding of the PhD dissertation that coined the term, and all related IETF RFCs. So to really discuss this topic it would require that all of the participants in the discussion be fully familiar with the aforementioned dissertation, and of course a deep technical understanding of the original design goals of the original HTTP 1.0 and the evolution of this protocol leading up to the recent 2.0 proposal, by reading __and understanding__ all the related RFCs.
For one thing a REST design can represent resources in any form, whether it's HTML, XML, JSON or a JPEG file and in general any representation that makes sense to the User Agent per the suggestions of the Accept and Content-Type headers. So representation is one aspect whilst the question actually relates to scalability and database access, which is wrongly assuming that all resources will be pulled from a database, and that is the __least__ ideal case.
The scalability of REST comes primarily from taking advantage of caching, but there are many other important reasons (related to the CAP theorem). This means that the representation of the resource must include all the required information to understand it (including it's "state" hence the term "REpresentational State Transfer". This means that any network component must not need to look beyond the resource metadata (basically the HTTP verb and headers) to decide what to do with it, hence it's faster and more secure just by definition. This is BTW the main draw back and main weakness to using SOAP, XML-RPC or other tunnelling-style protocols over HTTP, which would require peeking into the content of the package and understanding the tunnelled protocol (e.g. SOAP) to understand the intention of the request. Which brings us to the most important misunderstanding about HTTP: is a TRANSFER and NOT a transport protocol. Hence SOAP and XML-RPC are by definition trojan horses tunnelled over HTTP. They are extremely unreliable for anything beyond the scope of LAN and should be banned from use in large-scale implementations or for anything that should be considered Internet-scale.
Back to the original question, perhaps the best way to __begin__ to understand this is by example:
Suppose you have a typical business system which handles inventory and sales. In any such system you will find that there are many more READ requests than WRITE ones in a ration that usually exceeds 10:1. If you map this to your UI it is likely that you will have about 10 GETs for every one POST, PUT or DELETE. Furthermore, viewed from the resource modelling level, most if this data is either non-mutable or slowly mutable which could perfectly allow for caching.
Take an inventory item for example, you may think that inventory level is critical but in reality most business models can deal with a an old value, but it will depend on the nature of the item. For example, if you are selling items and unless the lead time is excessive, you are not going to stop a sale because you don't have sufficient inventory, business will generally prefer to sell and then handle a back-order process, so things like negative inventory quantities are quite common. On the other hand a spare part in a nuclear facility requires exact and real-time access to the inventory level of this part (known as safety stock) and this holds true for most reliability-centred operations.
So what is the resource? In this case it is usually the part record ro simply put un REST terms "the part" or the "item". How cacheable is it? it depends. Some parts will be more cacheable than others and some may be non-cacheable, forcing a request to the database to obtain the real-time value. This resource-cache definition maps directly to HTTP GET and caching directives, in other words, both the lead time and criticality of the part will determine for how long the network components (including the user agent) may cache each item resource. This means that only the first GET /part/{id} will actually fetch the info from the DB and construct a representation in some format that is cacheable by any component of the network. For example a JSON representation that is stored and propagated in an HTTP-based noSql system such as MongoDB. In other words, the resource is stored in a relational DB but after the first get it gets cached (for a given time frame according to the HTTP caching directives which are determined by the items lead time and criticality as stated above). From then on, any network component and/or user agent requiring this resource could obtain a local copy, whether in it's own cache (e.g. the browser's cache) or from some near-by network component who also holds a copy (e.g. a caching network proxy).
As another example take an invoice. An invoice is stored in the RDBMS as a master-detail record (a.k.a. one to many relationship). This means that EVERY TIME I need to fetch the invoice I must first query for the header data, get some other related data (e.g. customer info, billing and shipping addresses, etc.) and then query for each individual invoice-line to be able to construct the "invoice resource" which is ultimately what the consumer wants, and this may need to bring in some other related data as well (usually in the form a complex join or sub-query) . In other words RDBMS is very effective at storing complex and relational data but it's really ineffective at extracting, constructing and distributing this data across multiple nodes for millions of GET requests. And the worst part of this is that most system designers and programmers don't even realize that in the case of the invoice this data is NON MUTABLE, EVER. This means, that once stored in the RDBMS by the invoicing code, there could just be a simple trigger that de-normalizes this data and serializes it to a JSON structure that is easily distributable across thousands of nodes and NEVER have to go to the database again to retrieve this information.
This means that once the invoice resource is created it can have a cache forever header so not only user agents do not have to wait until the request makes it all the way down to the RDBMS and have to construct the de-normalized object each time. This resource will be ultimately cached in the Browser's cache and NEVER again (unless user cleans their cache) need to even consult the network to obtain a copy of it.
Ans this is just the tip of the iceberg but the point is that REST is a complete architectural design and you must be familiar with all the levels involved (e.g. network, user agents, HTTP), and not only talk about API design.
So basically to answer your question: in a typical RESTful design, most POST, PUT, DELETE will follow a different path than GET. In other words, non-idempotent (or "write") methods will usually route through some code and then to a RDBMS while most idempotent methods (or "reads") will route to near and cached resource storage (even local as is the case of a Browser), therefore dealing with the CAP theorem. Basically, a real RESTful system must be carefully designed to take advantage of caching and eventual consistency and be modelled in resources not API.
Thank you so much for that detailed answer!
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Cloudflare Identifies Query Planning Bottleneck in ClickHouse

Cloudflare recently described how a slowdown in its billing pipeline was traced to contention inside the query planning stage of ClickHouse. The team profiled the bottleneck and patched ClickHouse to replace an exclusive lock with a shared lock, drop the per-query copy of the parts list, and improve part filtering.
By Renato LosioHow OpenAI Built a Secure Windows Sandbox for Codex Agents
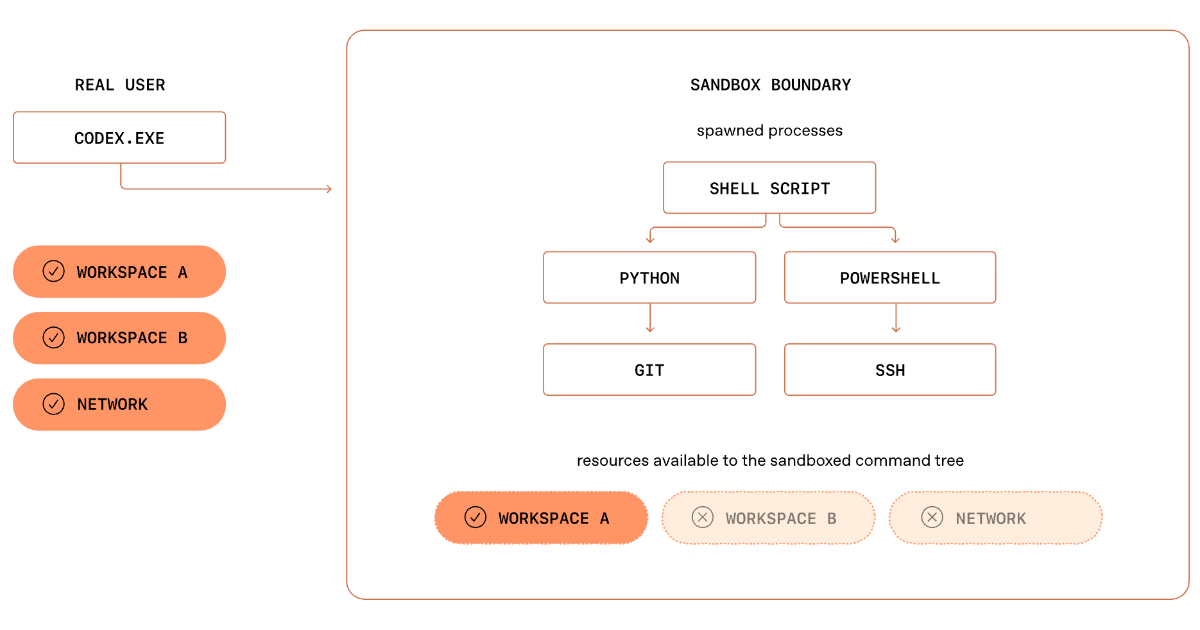
OpenAI details Codex Windows sandbox architecture, showing how SIDs, ACLs, restricted tokens, and dedicated sandbox accounts enable safe execution of autonomous coding tasks. The design balances isolation with real developer workflows and shows how OS security primitives must be composed for AI agents on local development environments.
By Leela KumiliPresentation: Platform Teams Enabling AI - MCP/Multi-Agentic Tools Across Linkedin

LinkedIn’s Karthik Ramgopal and Prince Valluri discuss leveraging AI as a new execution model for large-scale engineering. They explain how to move beyond fragmented implementations by building platform abstractions for orchestration, structured context, and safe tooling like MCP. They share architectural insights from real-world coding, observation, and UI testing agents built at LinkedIn.
By Karthik Ramgopal, Prince ValluriHow Netflix Maps Thousands of Microservices in Real-Time
Netflix has shared details about Service Topology. This internal system creates and updates a live dependency graph for thousands of microservices. It helps engineers see how services connect and resolve issues more quickly. The system merges three separate data sources into a single, queryable graph. It updates almost in real-time as traffic patterns shift.
By Claudio MasoloDropbox Introduces Nova, an Internal Platform for Running AI Coding Agents at Scale

Dropbox has unveiled Nova, an internal platform designed to orchestrate and operationalize AI coding agents across the company's engineering workflows.
By Craig Risi
© 2026 Created by Michael Levin.
Powered by
![]()