Codetown
Codetown ::: a software developer's community
- RJ Jansky
- Blog Posts
- Discussions
- Events
- Groups
- Photos
- Photo Albums
- Videos
RJ Jansky's Friends
RJ Jansky doesn't have any friends on yet.
RJ Jansky's Apps
RJ Jansky hasn't added any Apps yet.
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Inside Atlassian’s Forge Billing Architecture for Distributed Usage Tracking at Scale
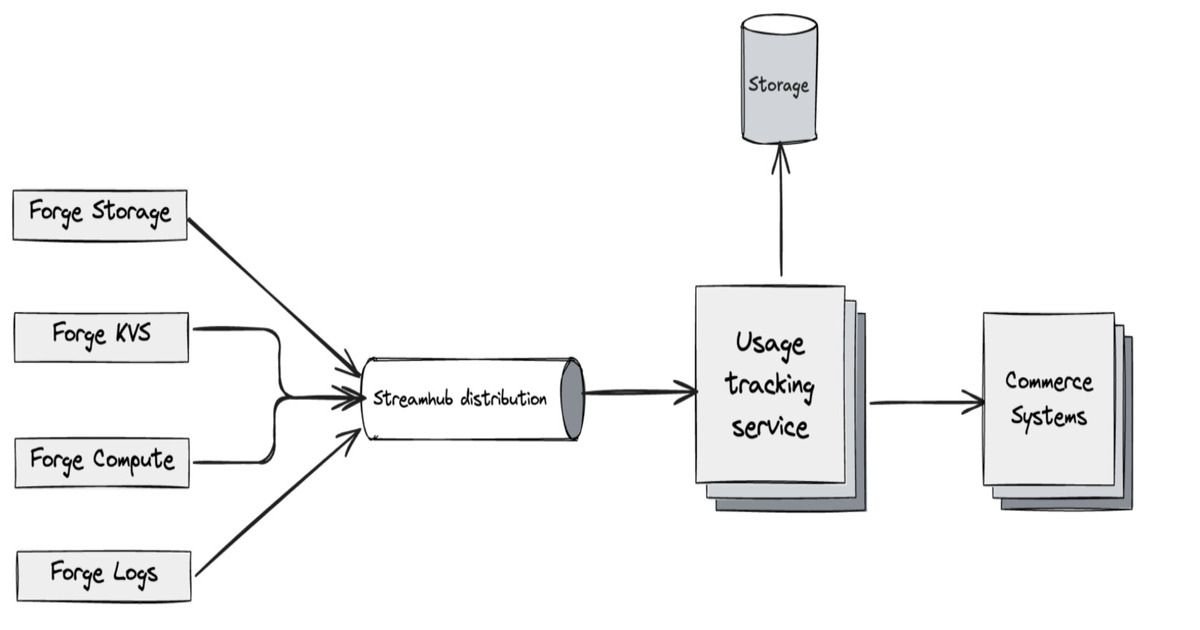
Atlassian details the Forge billing platform built for usage-based pricing across its cloud ecosystem. It processes large-scale usage events with correct attribution, deduplication, and aggregation using a streaming pipeline, idempotent processing, and layered storage to enable accurate billing, near real-time visibility, and reliable reconciliation across distributed services.
By Leela KumiliApple Launches Core AI for Apple-Silicon Optimized On-Device Generative AI

At WWDC 26, Apple announced the Core AI framework, the official successor to Core ML. It is designed to allow developers to run large language models and generative AI entirely on-device, supporting both custom-converted PyTorch models and pre-optimized open-source models.
By Sergio De SimoneClaude Fable 5 on Bedrock Requires Sharing Inference Data with Anthropic
Using Claude Fable 5 or Mythos 5 on Amazon Bedrock requires opting into provider_data_share, sending prompts and outputs to Anthropic for 30-day retention with human review. Previous Bedrock models kept inference data inside the AWS boundary. Three days after launch, Anthropic asked AWS to revoke access to both models citing US export control compliance.
By Steef-Jan WiggersAWS Adds Multi-Region Replication to Amazon Cognito Identity Service

AWS recently introduced Amazon Cognito multi-region replication, which automatically replicates user identities and user pool configurations from a primary region to a secondary one. This enables applications to continue authenticating users from a replica region during outages, without requiring custom replication and failover mechanisms.
By Renato LosioBehind the Scenes: Block 450 JVM Repositories Into Monorepo to Reduce Dependency Drift
Block, Inc. describes migrating ~450 JVM repositories into a monorepo across Cash App and Square engineering to reduce dependency drift and coordination overhead. The system supports ~8,800 weekly builds with ~10 min p90 CI time. The approach improves cross-service changes, build visibility, and developer experience through dependency graph–based builds, selective CI, and custom IDE tooling.
By Leela Kumili
© 2026 Created by Michael Levin.
Powered by
![]()