Codetown
Codetown ::: a software developer's community
Coroutine-First Android Architecture w/ Rick Busarow
Chicago Kotlin User Group x Android Listeners
Hosted at GrubHub, July 17
Coroutines are the new hot stuff, and right now they’re being added to lots of libraries. But what if you don’t want to use an alpha01 in production code? What can coroutines do on their own, right now? In this talk, we’ll discuss the power behind structured concurrency and how we can use it to make our entire stack lifecycle-aware. We’ll look at examples of how to turn any callback or long-running code into a coroutine, and we’ll go over when and how to use Channels to handle hot streams of data without leaking. Finally, and most importantly, we’ll see how we can use these tools to inform our application architecture, so that we can quickly write maintainable and testable features. Thanks to GrubHub for hosting!
Views: 55
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
AWS Introduces Amazon S3 Annotations

AWS recently announced Amazon S3 Annotations, a feature that lets teams attach rich, searchable context such as summaries, classifications, compliance data, or AI-generated insights directly to S3 objects. Annotations can be updated independently of the object and queried across datasets, reducing the need for separate metadata systems.
By Renato LosioClaude Reaches GA on Microsoft Foundry: European Enterprises Cannot Deploy It

Claude models reached GA on Microsoft Foundry with Azure-native billing and governance, but no European data zone exists. Anthropic's own documentation confirms data residency guarantees apply to Bedrock and Vertex AI but not Foundry. European practitioners from banking and healthcare report the offering is unapproved for production.
By Steef-Jan WiggersCycle Introduces EU Control Plane as Sovereignty Debate Continues
Cycle recently introduced a separate EU-based control plane, allowing European customers to keep platform management data and telemetry within Europe. The new offering is designed to improve compliance, operational isolation, and responsiveness for European organizations.
By Renato LosioCloudflare Details Unified Data Platform Where Billing Workloads Account for 53% of Queries
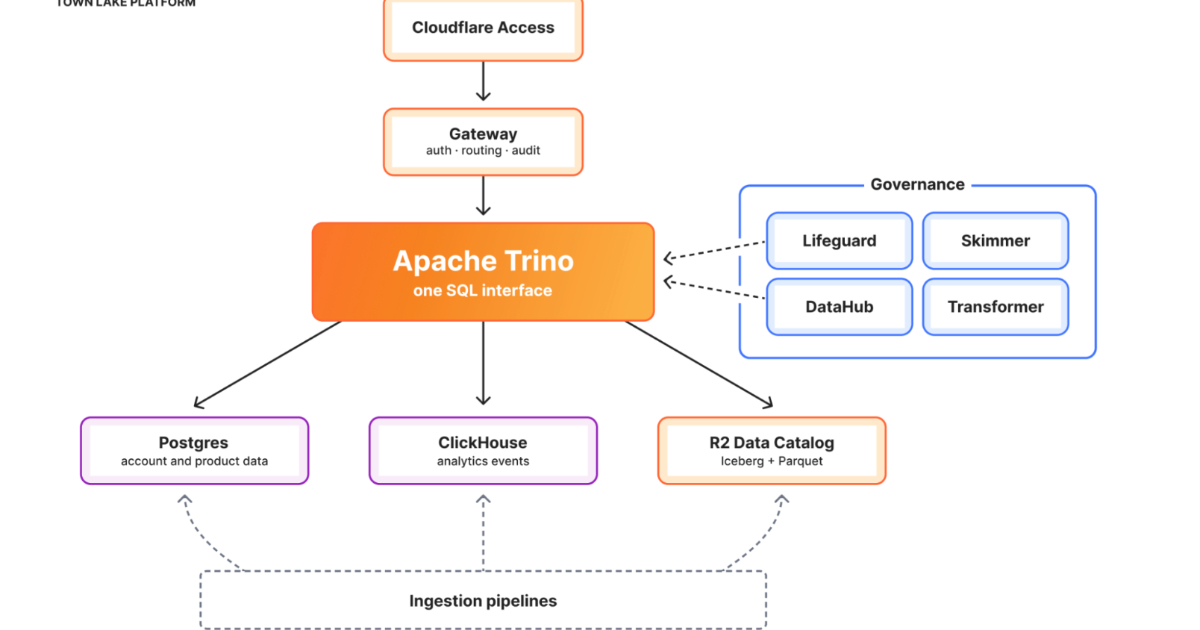
Cloudflare details Town Lake, an internal unified data platform, and Skipper, an AI analytics agent unifying access to operational, billing, security, and business data. The platform processed ~91K billing queries, with billing forming majority usage. Built on a lakehouse architecture using Trino, Iceberg, R2, and DataHub, it enables governed cross-system analytics and natural language access.
By Leela KumiliHardwood Promises High-Speed JVM Apache Parquet Processing with Zero Mandatory Dependencies
Hardwood, the project Gunnar Morling kick-started to improve the handling of Parquet files in Java, reached version 1. Its multi-threaded approach and zero mandatory external dependencies promise a simpler, optimal alternative to the Apache Parquet Java implementation. For now, the library provides a reading via API and a CLI for visualisation; writing support is expected in the upcoming versions.
By Olimpiu Pop
© 2026 Created by Michael Levin.
Powered by
![]()