Codetown
Codetown ::: a software developer's community
jaxjug July Meeting - Introduction to Spark
Event Details

Time: July 8, 2015 from 6pm to 8pm
Location: Availity
Street: 10752 Deerwood Park Blvd S, Ste 110
City/Town: Jacksonville FL 32256
Website or Map: http://maps.google.com/maps?q…
Phone: Eyalwir@ yahoo.com
Event Type: meeting
Organized By: Eyal Wir
Latest Activity: Jul 7, 2015
Event Description
Introduction to Spark
Presented by Carol McDonald, MapR Technologies
Apache Spark is a fast and general engine for large-scale data processing. In contrast to Hadoop's two-stage disk-based MapReduce paradigm, Spark's in-memory primitives provide performance up to 100 times faster for certain applications.
The Spark software stack includes a core data-proccessing engine, an interface for interactive querying, Sparkstreaming for streaming data analysis, and growing libraries for machine-learning and graph analysis. Spark is quickly establishing itself as a leading environment for doing fast, iterative in-memory and streaming analysis.
This talk will give an introduction the Spark stack, explain how Spark has lighting fast results, and how it complements Apache Hadoop.
Please RSVP!
http://www.meetup.com/Jacksonville-JAVA-User-Group-JaxJUG/events/223679551/
Comment Wall
Comment
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Anthropic Launches Claude Platform on AWS

Anthropic has announced the general availability of Claude Platform on AWS, a new deployment option that gives AWS customers direct access to Anthropic’s native Claude platform using AWS authentication, billing, and monitoring services.
By Daniel DominguezAirbnb Implements Context-Aware Identity Model to Support Privacy-First Social Features
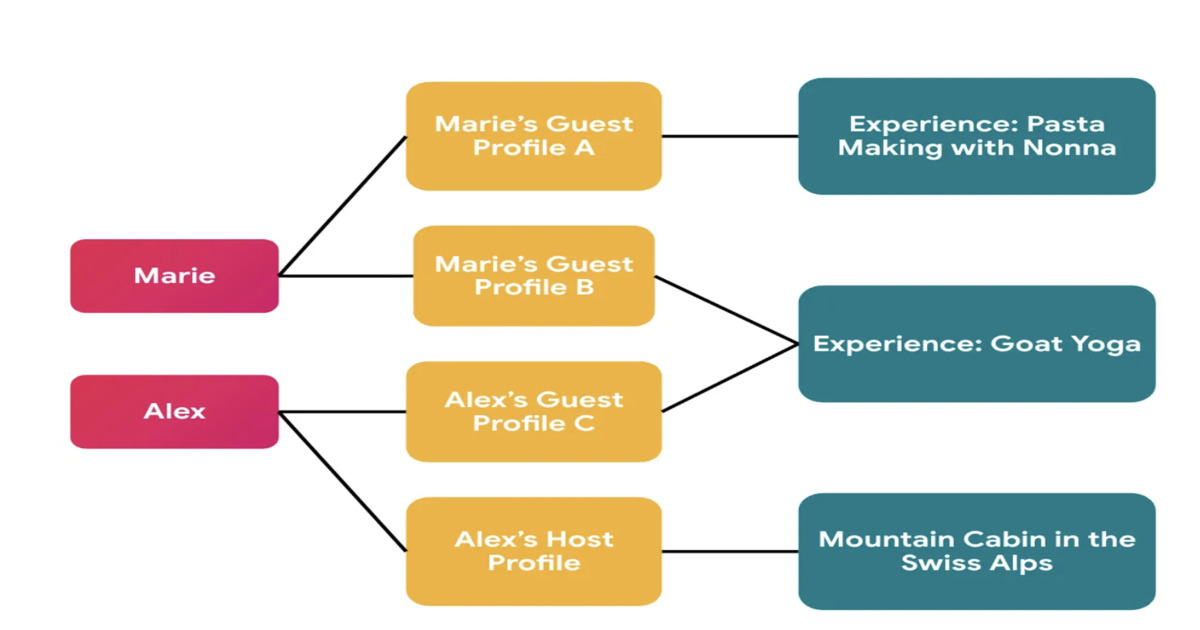
Airbnb has redesigned its identity system to support privacy-first social features in Experiences. The platform introduces context-specific profiles that separate global user identity from externally visible profiles, preventing cross-context linkage. The migration leveraged automated auditing, manual validation, and AI-assisted refactoring to enforce correct identity usage across services.
By Leela KumiliJEP 533 Tightens Exception Handling in Java's Structured Concurrency for JDK 27

JEP 533, Structured Concurrency, has reached integrated status for JDK 27. It refines exception handling and type safety in its API, particularly focusing on exception flow with a new ExecutionException type. Changes include an updated Joiner interface and a new open overload for easier configuration. The steady evolution signals ongoing development as feedback shapes the API.
By A N M Bazlur RahmanPresentation: What I Learned Building Multi-Agent Systems From Scratch

Paulo Arruda discusses Shopify’s evolution in AI adoption, moving from simple chat tools to a sophisticated swarm of specialized agents. He explains the transition from massive "all-in-one" prompts to lean, narrow-focused agent microservices that slash task times from hours to minutes. He also shares a future-looking hypothesis on using filesystem-based adapters to solve context bloat.
By Paulo ArrudaArticle: The Mathematics of Backlogs: Capacity Planning for Queue Recovery

Backlogs in distributed systems are arithmetic problems, not mysteries. This article provides practical formulas for calculating backlog drain time, sizing consumer headroom, and setting auto-scaling triggers. It covers key failure modes — retry amplification, metastable states, and cascading pipeline bottlenecks — plus when to shed load instead of draining.
By Rajesh Kumar Pandey
© 2026 Created by Michael Levin.
Powered by
![]()
RSVP for jaxjug July Meeting - Introduction to Spark to add comments!
Join Codetown