Codetown
Codetown ::: a software developer's community
Small Businesses Can Meet the Challenges of Data Conversion
Implementing new data systems is a difficult process sometimes. New systems result in some amazing benefits including improved processes and the ability to access data more easily, but they are also going to need data to be converted to a format that can be used in the new system. This is a challenge that small businesses must face. This post will look at 5 challenges of data conversion to ensure that you are prepared to conquer them!
Scope of Data
The first step is to define the scope of the data to determine how much of it needs to be converted. You’ll likely find that some of it is essentially useless so there is no need to convert that. Make a list and double check it. How much data is being converted? How much of this data must be converted manually? Determining the scope of data that needs to be converted is a critical step because it allows you to create a plan of action.
Data Sources and Destinations Need to Be Defined
Now you will have to determine exactly where the data is coming from. Are you pulling it from different databases or have you consolidated everything into a single database? You must clearly define the source.
Once you know the source, identify the destination for the data. This will determine exactly what type of conversion is necessary. In some cases, there might be more than one destination so you’ll need to identify what data goes into specific destinations. Write all of this down.
It’s Easy to Get Lost in the Complexity
There is so much data that is accumulated by a business that it’s easy to get lost in a sea of raw data. The sheer intimidation of all this data is what leads to many entrepreneurs to procrastinate updating their systems. They simply don’t want to deal with all of this data conversion.
However, there is a way to face this challenge – data mapping. This is seen by many experts as an essential step to successful data conversion. Detail the requirements for each element of data within the conversion. You’ll have a list by this point to help make this easier. Define all of the following details:
- What will business processes be affected by the change?
- What will the overall transformation look like?
- What new data inputs can you incorporate to meet the needs of the new system?
Every element of the conversion must be documented and mapped out in detail. This includes the estimated time to implement each change.
Determining Everyone’s Roles
This is another challenge that can become a major bottleneck in the overall conversion of data. I’ve seen companies forget to define everyone’s roles during the conversion so they all do their own thing, resulting in an even bigger mess. It’s essential that you detail every team member’s roles before you begin the data conversion process.
- Who will be validating the new data?
- Who will input data into the new system in order to keep the business running?
- Who needs to be locked out of the system until the conversion is finished?
What Resources Are Required?
Finally, you’ll have to make a list of every resource required throughout the data conversion process. Develop a full plan of action from beginning to end including development, testing, and validating new data. Then make sure that you review this plan in detail with all associates involved.
Keeping your systems up-to-date is important because the business world continues to grow at a record pace. If you can meet all of the challenges in this post, then you will find that it’s not quite as intimidating as you believed.
Comment
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
AWS Introduces Amazon S3 Annotations

AWS recently announced Amazon S3 Annotations, a feature that lets teams attach rich, searchable context such as summaries, classifications, compliance data, or AI-generated insights directly to S3 objects. Annotations can be updated independently of the object and queried across datasets, reducing the need for separate metadata systems.
By Renato LosioClaude Reaches GA on Microsoft Foundry: European Enterprises Cannot Deploy It

Claude models reached GA on Microsoft Foundry with Azure-native billing and governance, but no European data zone exists. Anthropic's own documentation confirms data residency guarantees apply to Bedrock and Vertex AI but not Foundry. European practitioners from banking and healthcare report the offering is unapproved for production.
By Steef-Jan WiggersCycle Introduces EU Control Plane as Sovereignty Debate Continues
Cycle recently introduced a separate EU-based control plane, allowing European customers to keep platform management data and telemetry within Europe. The new offering is designed to improve compliance, operational isolation, and responsiveness for European organizations.
By Renato LosioCloudflare Details Unified Data Platform Where Billing Workloads Account for 53% of Queries
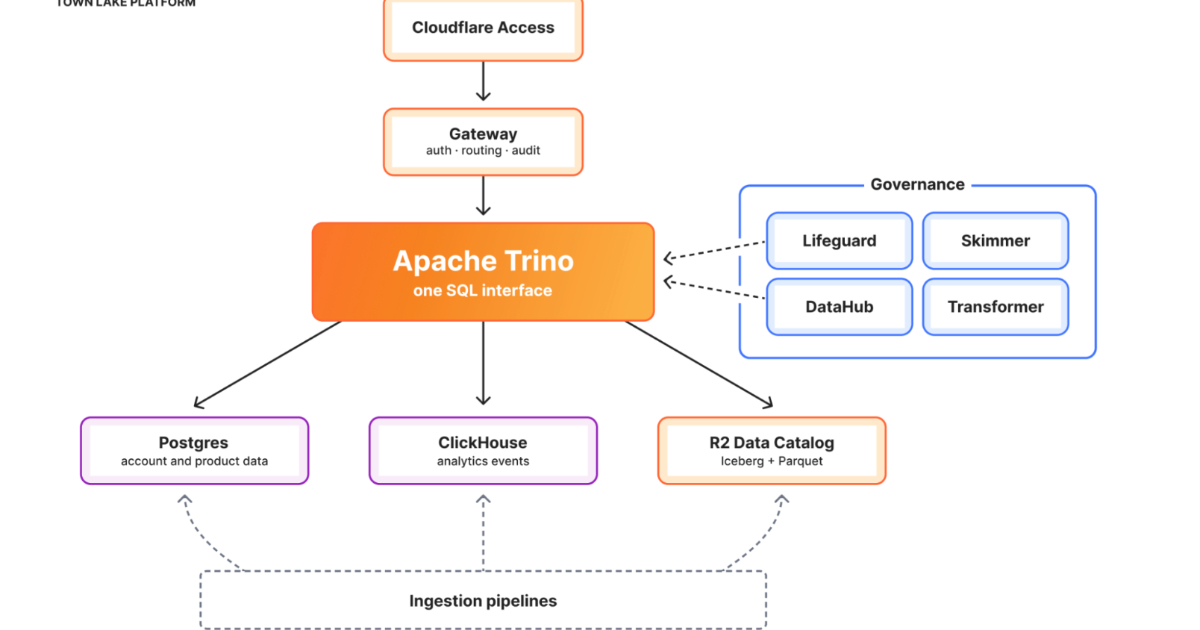
Cloudflare details Town Lake, an internal unified data platform, and Skipper, an AI analytics agent unifying access to operational, billing, security, and business data. The platform processed ~91K billing queries, with billing forming majority usage. Built on a lakehouse architecture using Trino, Iceberg, R2, and DataHub, it enables governed cross-system analytics and natural language access.
By Leela KumiliHardwood Promises High-Speed JVM Apache Parquet Processing with Zero Mandatory Dependencies
Hardwood, the project Gunnar Morling kick-started to improve the handling of Parquet files in Java, reached version 1. Its multi-threaded approach and zero mandatory external dependencies promise a simpler, optimal alternative to the Apache Parquet Java implementation. For now, the library provides a reading via API and a CLI for visualisation; writing support is expected in the upcoming versions.
By Olimpiu Pop
© 2026 Created by Michael Levin.
Powered by
![]()
You need to be a member of Codetown to add comments!
Join Codetown