Codetown
Codetown ::: a software developer's community
Mashup Patterns
Comment
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Presentation: Confidently Automating Changes Across a Diverse Fleet

Netflix engineer Casey Bleifer shares how to achieve rapid, automated code changes across a massive, diverse software fleet. She discusses building an event-driven orchestration platform using composable, Lego-like steps, and explains how Netflix utilizes automated canary validation, compliance checks, and a custom "confidence metric" to eliminate the long tail of manual engineering migrations.
By Casey BleiferIBM Vault Enterprise 2.0 Brings Automated LDAP Secrets Management to Enterprise Identity Security

IBM and HashiCorp have announced new LDAP secrets management capabilities in IBM Vault Enterprise 2.0, introducing a redesigned architecture to manage LDAP credentials, support password rotation, and automate the identity lifecycle.
By Craig RisiMicrosoft Foundry Adds Runtime, Tooling, and Governance for Production Agents

Microsoft used their Build 2026 event to announce new functionality for Microsoft Foundry. Citing Foundry as "the place where AI agents move from experiments to production systems," in a blog post, Nick Brady writes that the release brings “runtime, tools, memory, grounding, models, observability, and governance” that developers need for production agents, rather than just new model endpoints.
By Matt SaundersAWS Releases Next Generation of Amazon OpenSearch Serverless

Amazon Web Services has recently announced the general availability of the next generation of Amazon OpenSearch Serverless, with a redesigned architecture that enables 20 times faster resource provisioning than the previous serverless architecture, true scale-to-zero capability, and up to 60% lower cost than a provisioned cluster for peak loads.
By Gianmarco NalinPinterest Uses Content Fingerprints for URL Deduplication Across Millions of Domains
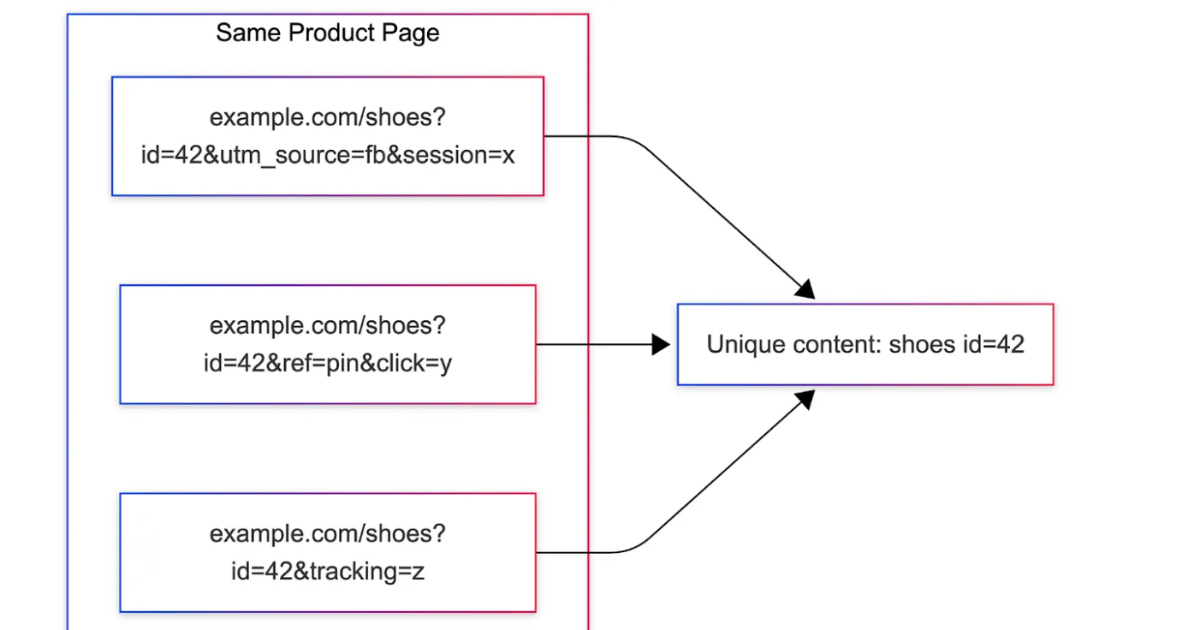
Pinterest introduced MIQPS, a URL normalization system that identifies which query parameters affect page identity using rendered content fingerprints. It reduces duplicate processing across millions of domains by replacing rule-based approaches with offline analysis, anomaly detection, and runtime parameter maps, improving ingestion efficiency and scalability in large-scale content pipelines.
By Leela Kumili
© 2026 Created by Michael Levin.
Powered by
![]()
You need to be a member of Codetown to add comments!
Join Codetown