Codetown
Codetown ::: a software developer's community
Kotlin Thursdays - Introduction to Functional Programming Part 2

Resources
- Higher-Order Functions and Lambdas:https://kotlinlang.org/docs/reference/lambdas.html
- FP in Kotlin Part 1: https://medium.com/kotlin-thursdays/functional-programming-in-kotli...
Introduction
Last week, we went over higher order functions in Kotlin. We learned how higher order functions can accept functions as parameters and are also able to return functions. This week, we will take a look at lambdas. Lambdas are another type of function and they are very popular in the functional programming world.
Logic & Data
Computer programs are made up of two parts: logic and data. Usually, logic is described in functions and data is passed to those functions. The functions do things with the data, and return a result. When we write a function we would typically create a named function. As we saw last week, this is a typical named function:
fun hello(name: String): String {
return "Hello, $name"
}
Then you can call this function:
fun main() {
println(hello("Matt"))
}
Which gives us the result:
Hello, Matt
Functions as Data
There is a concept in the functional programming world where functions are treated as data. Lambdas (functions as data) can do the same thing as named functions, but with lambdas, the content of a given function can be passed directly into other functions. A lambda can also be assigned to a variable as though it were just a value.
Lambda Syntax
Lambdas are similar to named functions but lambdas do not have a name and the lambda syntax looks a little different. Whereas a function in Kotlin would look like this:
fun hello() {
return "Hello World"
}
The lambda expression would look like this:
{ "Hello World" }
Here is an example with a parameter:
fun(name: String) {
return "Hello, ${name}"
}
The lambda version:
{ name: String -> "Hello, $name" }
You can call the lambda by passing the parameter to it in parentheses after the last curly brace:
{ name: String -> "Hello, $name" }("Matt")
It’s also possible to assign a lambda to a variable:
val hello = { name: String -> "Hello, $name" }
You can then call the variable the lambda has been assigned to, just as if it was a named function:
hello("Matt")
Lambdas provide us with a convenient way to pass logic into other functions without having to define that logic in a named function. This is very useful when processing lists or arrays of data. We’ll take a look at processing lists with lambdas in the next post!
Views: 166
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Java News Roundup: Hardwood 1.0, Endive 1.0, Azul Payara, Quarkus, WildFly, LangChain4j, OSSI

This week's Java roundup for June 22nd, 2026, features news highlighting: the GA releases of Hardwood 1.0 and Endive 1.0; the June 2026 edition of Azul Payara; point releases of Quarkus, LangChain4j; the first beta release of WildFly 41; and introducing Eliya JDK and the Open Source Sustainability Initiative (OSSI), the latter of which was founded by HeroDevs and Commonhaus Foundation.
By Michael RedlichEliya 25 Brings a JVM-Level Diagnostic Profile to OpenJDK 25 LTS

Asymm Systems has released Eliya 25.0.3, an OpenJDK 25 LTS distribution aimed at improving production diagnostics in Java environments. It consolidates several HotSpot features into an opt-in Production profile. Eliya is designed for teams needing reliable diagnostic data, especially in regulated settings. Future enhancements are planned for Phase 2.
By A N M Bazlur RahmanInside Target’s LLM-Based System for Semantic Matching in Marketing Forecast Pipelines
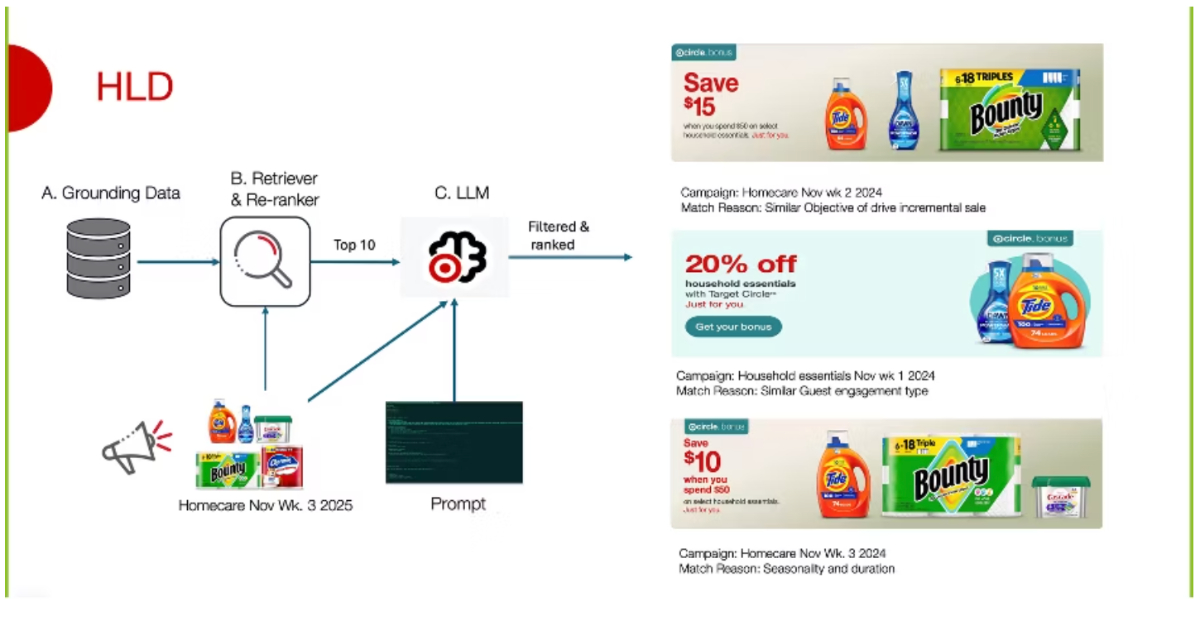
Target built a generative AI system to improve marketing campaign forecasting by retrieving and ranking similar historical campaigns. Using embeddings, vector search, and LLM ranking, it replaces rule-based workflows. Evaluation shows 75% top-1 and 100% top-3 coverage. The system reduces manual effort, improves consistency, and uses feedback loops to refine retrieval using campaign outcomes.
By Leela KumiliPresentation: Million PDFs: Building a Modern Document Infrastructure with Rust and Typst

Erik Steiger discusses the operational pain of legacy PDF generation in regulated banking and manufacturing. He explains how transitioning from resource-heavy engines like Puppeteer and LaTeX to a serverless Rust architecture powered by Typst can drop render latencies below 2ms. He shares how applying Git and Docker concepts to template registries ensures ironclad compliance and rapid debugging.
By Erik SteigerPodcast: Architectural Patterns: Moving Beyond Cloud-Native to Local-First - Insights from Adam Wiggins
In this episode, Heroku co-founder and Ink & Switch founder Adam Wiggins argues for a 'local-first' architecture that reconciles cloud-based collaboration with the performance and data ownership of local software. He explores the role of CRDTs and version control primitives in non-code domains, and examines how a hybrid AI future might leverage local models for core productivity tasks.
By Adam Wiggins
© 2026 Created by Michael Levin.
Powered by
![]()