Codetown
Codetown ::: a software developer's community
Graph Databases
Are you interested in learning about graph databases? The folks at Neo4J published a book and it's free! Here's a link to the download page: http://graphdatabases.com/
Views: 114
Replies to This Discussion
-
Permalink Reply by Juan Rolando Reza on
-
Database representation of graph-structured information is fascinating in its own right.
I have been studying genomics technology in which graphs play a big role, both as information-structure that is the basis of certain algorithms, as well as the data driving visualizations or visually-interesting real-world structures.
As an example, here is a visualization of a protein complex that catches the eye.
See http://en.wikipedia.org/wiki/FOXP2#/media/File:Protein_FOXP2_PDB_2a...
The image is a Richardson diagram which is (mostly) automatically generated from a database describing the molecular structure of the protein. This type of diagram was invented (i.e. originally hand-drawn) by Jane Richardson, PhD.
I wonder if the book "Graph Databases" touches on this.
Presently, I am doing a research study on a particular feature of the epigenome. It involves large DNA databases (actually, structured flat files), elaborate algorithms for sequence correlation, and histone complexes. Each of these involves graph-theoretic representations and inference functions from graph structures.
The "databases" I know for DNA, the transcriptome, pathways, etc. do not lend themselves to conventional SQL, or even noSQL as far as I know to date. (Chime in anyone? )
I will be presenting a paper at the IEEE SouthCon conference in April 2015 which touches on a graph-theoretic feature of certain (sequencing) problems lending itself to massively-parallel-ization of linearly-expressable algorithms.
I am pleased to see a free book on graph databases. Thanks!
-
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Anthropic Launches Claude Platform on AWS

Anthropic has announced the general availability of Claude Platform on AWS, a new deployment option that gives AWS customers direct access to Anthropic’s native Claude platform using AWS authentication, billing, and monitoring services.
By Daniel DominguezAirbnb Implements Context-Aware Identity Model to Support Privacy-First Social Features
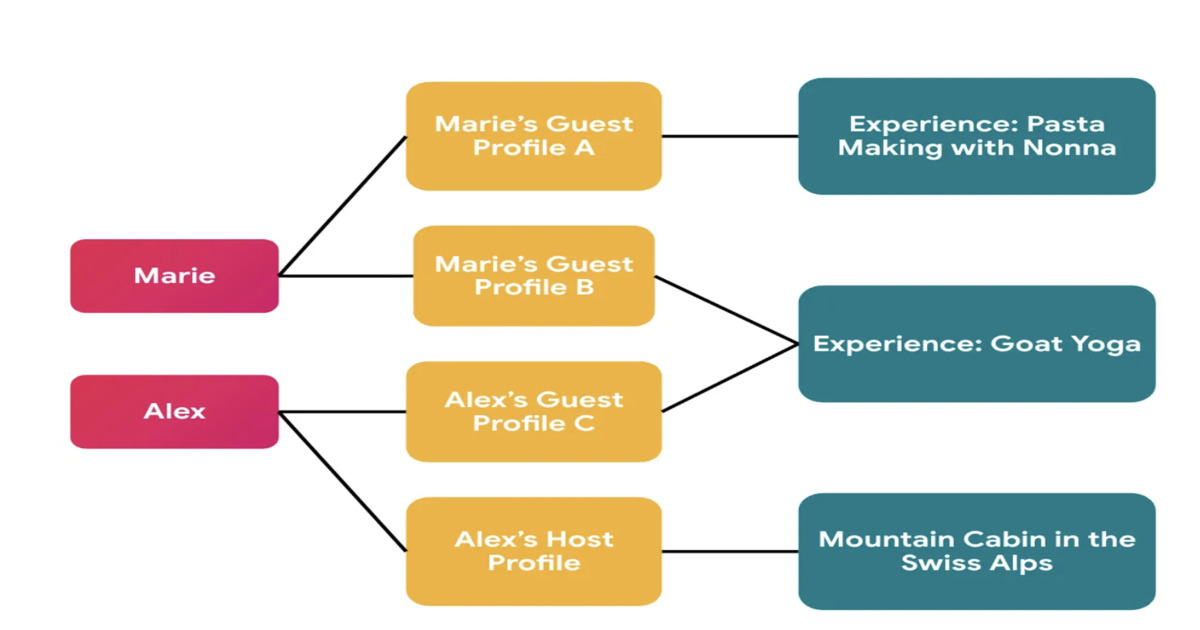
Airbnb has redesigned its identity system to support privacy-first social features in Experiences. The platform introduces context-specific profiles that separate global user identity from externally visible profiles, preventing cross-context linkage. The migration leveraged automated auditing, manual validation, and AI-assisted refactoring to enforce correct identity usage across services.
By Leela KumiliJEP 533 Tightens Exception Handling in Java's Structured Concurrency for JDK 27

JEP 533, Structured Concurrency, has reached integrated status for JDK 27. It refines exception handling and type safety in its API, particularly focusing on exception flow with a new ExecutionException type. Changes include an updated Joiner interface and a new open overload for easier configuration. The steady evolution signals ongoing development as feedback shapes the API.
By A N M Bazlur RahmanPresentation: What I Learned Building Multi-Agent Systems From Scratch

Paulo Arruda discusses Shopify’s evolution in AI adoption, moving from simple chat tools to a sophisticated swarm of specialized agents. He explains the transition from massive "all-in-one" prompts to lean, narrow-focused agent microservices that slash task times from hours to minutes. He also shares a future-looking hypothesis on using filesystem-based adapters to solve context bloat.
By Paulo ArrudaArticle: The Mathematics of Backlogs: Capacity Planning for Queue Recovery

Backlogs in distributed systems are arithmetic problems, not mysteries. This article provides practical formulas for calculating backlog drain time, sizing consumer headroom, and setting auto-scaling triggers. It covers key failure modes — retry amplification, metastable states, and cascading pipeline bottlenecks — plus when to shed load instead of draining.
By Rajesh Kumar Pandey
© 2026 Created by Michael Levin.
Powered by
![]()