Codetown
Codetown ::: a software developer's community
What is Computational Linguistics?
Views: 217
Replies to This Discussion
-
Permalink Reply by Jim White on
-
Commercial applications of computational linguistics have been growing by leaps and bounds. IBM created a new poster child for the field with their Jeopardy champion Watson, and most everyone has used Google Translate and/or Voice by now (and fewer yet will have escaped interacting with an Automated Voice Response system). Commercial segments making significant use of NLP include web marketing, medicine, biomedical research, finance, law, and customer call centers.
In the most general terms, computational linguistics is applying computational methods to problems in linguistics. Linguistics then is the study of human language in all its aspects. Although it hasn't received a lot of press until recently, computational linguistics has been around pretty much since the development of the computer. One of the first uses of digital computers (and a key impetus for their development) was in code breaking, which is an application of "compling" (I know, it looks like a typo for "compiling" but CL looks like Common LISP to me). The Association for Computational Linguistics (ACL), the largest and oldest scientific and profssional society in the field, will hold its 50th annual conference next July.
Being such a broad field there are of course many specializations and various communities with differing objectives and vocabularies. Folks primarily focused on engineering computer systems that process human language at a level deeper than simply character strings are generally under the Natural Language Processing (NLP) banner. The commercial success of CL applications and the focus on some problems other than the traditional NLP ones (translation, text understanding, and speech recognition and generation) has spawned Text Analytics as another subfield that is closely associated with Business Intelligence (itself largely commercial application of machine learning methods). Perhaps the biggest focus of Text Analytics has been on sentiment analysis, which assesses a speaker's attitude or mood in something they've said or written (we usually say "speaker" even when the medium is written or typed). There are many businesses that use sentiment analysis on the web to find out what folks are saying about them and their products, in call centers for quality control, and in finance to predict future prices. Applications in law and government include "e-discovery" and smart OCR systems. Lastly, and far from leastly, is compling in the medical field and the specialized domain knowledge it calls for which is known as bioinformatics. Bioinformatics may well be compling's "killer app" because of the tremendous opportunity to do good. Answering technical questions for medical practitioners is the application IBM has targeted as Watson's "day job".
This is a big topic and I have lots I would like to say, so I intend to drop in here often. So stay tuned!~~~~ Jim White
-
-
Permalink Reply by John Considine on
-
On a similar note: This fall a colleague of mine informed me of a class being offered by two Standford professors. It is Introduction to Artifical Intelligence (ai-class.com). I signed up for the course along with 138,000 other students. It has been interesting to see some of the therories and formulas used to help the computer find the correct answer. Prior to starting the class, I did not realize it is mostly related to statistics. I just finished the midterm and will hopfully learn alot more as the course continues.
-
-
Permalink Reply by Eric Lavigne on
-
Next semester Stanford is offering a wider variety of online courses. One of them is specifically on natural language processing:
There are also some other courses that would make good follow-ups to the AI course.
Machine learning: http://jan2012.ml-class.org/
Probabilistic graphical models: http://www.pgm-class.org/ (These are the kinds of graphs you saw in the AI course - not about pictures)
Game theory: http://www.game-theory-class.org/
-
-
Permalink Reply by Michael Levin on
-
Excellent. Thanks, Eric!
Eric Lavigne said:Next semester Stanford is offering a wider variety of online courses. One of them is specifically on natural language processing:
There are also some other courses that would make good follow-ups to the AI course.
Machine learning: http://jan2012.ml-class.org/
Probabilistic graphical models: http://www.pgm-class.org/ (These are the kinds of graphs you saw in the AI course - not about pictures)
Game theory: http://www.game-theory-class.org/
-
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
.NET 11 Preview 5: Brings File-Based App Improvements, New C# Features, and a Blazor Validation Wave
Microsoft has released the fifth preview of .NET 11, with updates across the SDK, C#, ASP.NET Core, .NET MAUI, and EF Core. Highlights include file-based app improvements, new C# closed classes and unions, a Blazor validation wave, a large MAUI reliability rollup, and SQL Server 2022 as the default EF Core compatibility level.
By Almir VukGitLab 19.0 Embeds Agentic AI in Secrets, Merge Requests, and Supply Chain Security

GitLab 19.0 extends agentic AI beyond code generation into securing credentials, reviewing and merging changes, and scanning dependencies, adding a public beta Secrets Manager, a full merge request Developer Flow, usage-based GitLab Duo billing, and generally available SBOM dependency scanning.
By Mark SilvesterWindows Platform Security and the Race to Secure AI Agents

In a new Windows Developer Blog post titled "Windows platform security for AI agents", Microsoft positions Windows as the trustworthy operating system for autonomous agents and introduces the Microsoft Execution Containers (MXC) SDK as the core of that strategy. The post argues that containment, identity and manageability must be built into the operating system.
By Matt SaundersFrom Camera to Cloud: Netflix’s Scalable Media Processing Pipeline
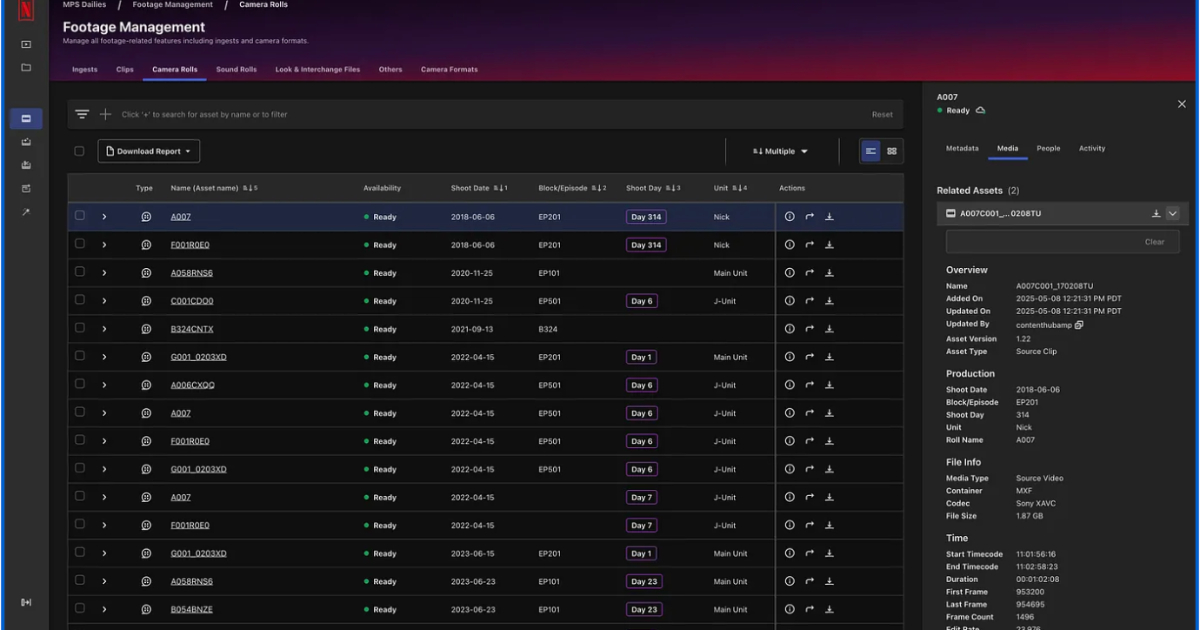
Netflix has detailed a cloud-based system for scaling camera file processing across global film and TV workflows. The pipeline handles ingest, validation, metadata extraction, and media transformation at scale using FilmLight API and distributed compute. It standardizes workflows across editorial, VFX, and color pipelines, improving consistency and reducing manual handling across productions.
By Leela KumiliPresentation: Write-Ahead Intent Log: A Foundation for Efficient CDC at Scale

Vinay Chella and Akshat Goel discuss the challenges of running traditional CDC across heterogeneous databases during peak order traffic. They explain how Debezium hit limits under high load and share how they built Write-Ahead Intent Log (WAIL) - a custom architecture that utilizes a dumb producer proxy and a smart consumer pattern to cleanly separate the intent from the state payload.
By Vinay Chella, Akshat Goel
© 2026 Created by Michael Levin.
Powered by
![]()