Codetown
Codetown ::: a software developer's community
Kotlin Thursdays - Introduction to Functional Programming Part 2

Resources
- Higher-Order Functions and Lambdas:https://kotlinlang.org/docs/reference/lambdas.html
- FP in Kotlin Part 1: https://medium.com/kotlin-thursdays/functional-programming-in-kotli...
Introduction
Last week, we went over higher order functions in Kotlin. We learned how higher order functions can accept functions as parameters and are also able to return functions. This week, we will take a look at lambdas. Lambdas are another type of function and they are very popular in the functional programming world.
Logic & Data
Computer programs are made up of two parts: logic and data. Usually, logic is described in functions and data is passed to those functions. The functions do things with the data, and return a result. When we write a function we would typically create a named function. As we saw last week, this is a typical named function:
fun hello(name: String): String {
return "Hello, $name"
}
Then you can call this function:
fun main() {
println(hello("Matt"))
}
Which gives us the result:
Hello, Matt
Functions as Data
There is a concept in the functional programming world where functions are treated as data. Lambdas (functions as data) can do the same thing as named functions, but with lambdas, the content of a given function can be passed directly into other functions. A lambda can also be assigned to a variable as though it were just a value.
Lambda Syntax
Lambdas are similar to named functions but lambdas do not have a name and the lambda syntax looks a little different. Whereas a function in Kotlin would look like this:
fun hello() {
return "Hello World"
}
The lambda expression would look like this:
{ "Hello World" }
Here is an example with a parameter:
fun(name: String) {
return "Hello, ${name}"
}
The lambda version:
{ name: String -> "Hello, $name" }
You can call the lambda by passing the parameter to it in parentheses after the last curly brace:
{ name: String -> "Hello, $name" }("Matt")
It’s also possible to assign a lambda to a variable:
val hello = { name: String -> "Hello, $name" }
You can then call the variable the lambda has been assigned to, just as if it was a named function:
hello("Matt")
Lambdas provide us with a convenient way to pass logic into other functions without having to define that logic in a named function. This is very useful when processing lists or arrays of data. We’ll take a look at processing lists with lambdas in the next post!
Views: 164
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Kubernetes v1.36: Security Defaults Tighten as AI Workload Support Matures

Kubernetes v1.36, released in 2026, includes 70 enhancements focused on security, AI workloads, and API scalability. Key features graduating to General Availability are User Namespaces, Mutating Admission Policies, and Fine-Grained Kubelet API Authorization. The release also addresses workload management and introduces new features for AI resource allocations.
By Matt SaundersAnthropic Launches Claude Platform on AWS

Anthropic has announced the general availability of Claude Platform on AWS, a new deployment option that gives AWS customers direct access to Anthropic’s native Claude platform using AWS authentication, billing, and monitoring services.
By Daniel DominguezAirbnb Implements Context-Aware Identity Model to Support Privacy-First Social Features
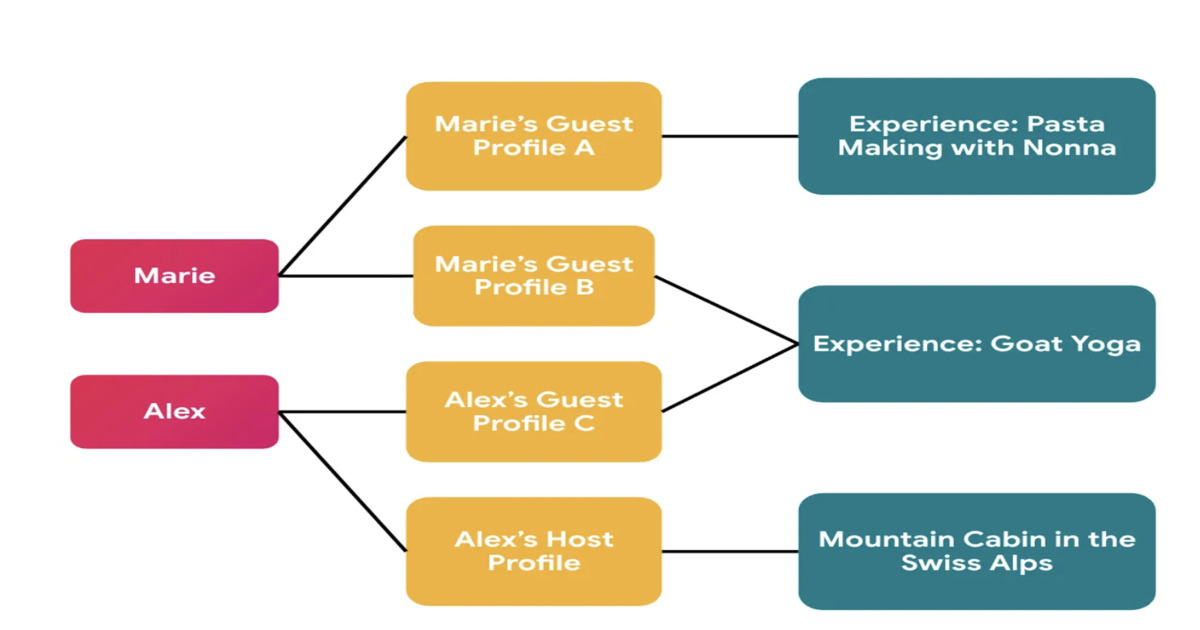
Airbnb has redesigned its identity system to support privacy-first social features in Experiences. The platform introduces context-specific profiles that separate global user identity from externally visible profiles, preventing cross-context linkage. The migration leveraged automated auditing, manual validation, and AI-assisted refactoring to enforce correct identity usage across services.
By Leela KumiliJEP 533 Tightens Exception Handling in Java's Structured Concurrency for JDK 27

JEP 533, Structured Concurrency, has reached integrated status for JDK 27. It refines exception handling and type safety in its API, particularly focusing on exception flow with a new ExecutionException type. Changes include an updated Joiner interface and a new open overload for easier configuration. The steady evolution signals ongoing development as feedback shapes the API.
By A N M Bazlur RahmanPresentation: What I Learned Building Multi-Agent Systems From Scratch

Paulo Arruda discusses Shopify’s evolution in AI adoption, moving from simple chat tools to a sophisticated swarm of specialized agents. He explains the transition from massive "all-in-one" prompts to lean, narrow-focused agent microservices that slash task times from hours to minutes. He also shares a future-looking hypothesis on using filesystem-based adapters to solve context bloat.
By Paulo Arruda
© 2026 Created by Michael Levin.
Powered by
![]()