Codetown
Codetown ::: a software developer's community
Wikipedia Place
Information
We've had a unique opportunity to speak with Brion Vibber recently at the October Orlandojug meeting. Let's discuss what we learned for those who couldn't attend and to expand on what we heard. We'll discuss technical and socio-cultural topics.
Members: 9
Latest Activity: Oct 27, 2011
About Wikipedia Place
Wikipedia is arguably the most popular and high volume site on the web. Brion Vibber has been the tech guy since the start. He described the initial architecture on Swampcast as just a couple of LAMP servers in Tampa. Since then the architecture has evolved and many lessons have been learned.
There are also workflow, ancillary sites, the community aspect and many other aspects of Wikipedia we can learn from and even influence in the future.
(book photo from FromOldBooks)
Discussion Forum
Wikipedia Architecture - High Level View
The Wikipedia website began as a couple of LAMP servers. Brion described the wiki he chose and other details in the…Continue
Tags: vibber, performance, LAMP, swampcast, architecture
Started by Michael Levin Nov 2, 2009.
Wikipedia Place Reading List
![]() Loading feed
Loading feed
Comment Wall
Comment
Happy 10th year, JCertif!
Notes
Welcome to Codetown!
 Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Codetown is a social network. It's got blogs, forums, groups, personal pages and more! You might think of Codetown as a funky camper van with lots of compartments for your stuff and a great multimedia system, too! Best of all, Codetown has room for all of your friends.
Created by Michael Levin Dec 18, 2008 at 6:56pm. Last updated by Michael Levin May 4, 2018.
Looking for Jobs or Staff?
Check out the Codetown Jobs group.
InfoQ Reading List
Cloudflare Introduces Data Platform with Zero Egress Fees
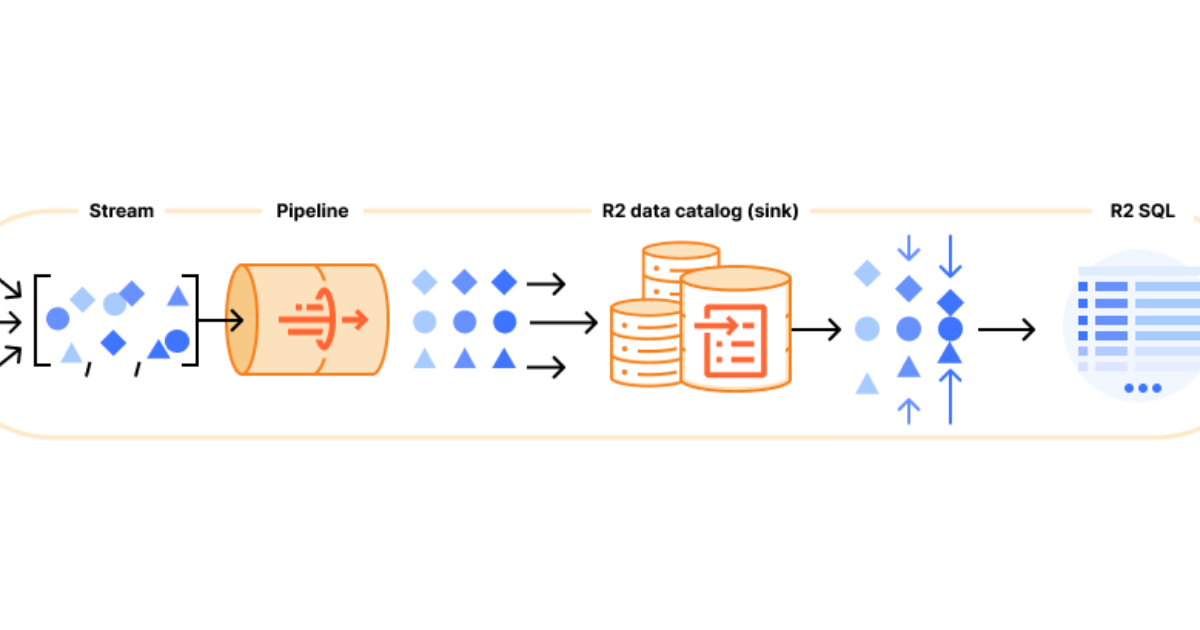
Cloudflare has recently announced the open beta of Cloudflare Data Platform, a managed solution for ingesting, storing, and querying analytical data tables using open standards such as Apache Iceberg.
By Renato LosioLayered Defences Are Key to Combating AI-Driven Cyber Threats, CNCF Report Finds

The Cloud Native Computing Foundation have published an analysis of modern cybersecurity practices, finding that attacks using Artificial Intelligence are now a significant threat. The report highlights the criticality for organisations to adopt multi-layered defence strategies as artificial intelligence transforms both the threat landscape and the protective measures available to businesses.
By Matt SaundersApple Previews SDK for Building Android Apps with Swift

The Swift SDK for Android, recently released as a nightly build, is designed to help developers to port their Swift packages to Android, making it easier to share code across platforms. While the SDK is still in preview, over 25% of packages in the Swift Package Index can already be compiled for Android.
By Sergio De SimonePresentation: The Way We Manage Compliance Is Wrong… And Is Changing! Bringing DevOps Principles to Controls and Audit

Ian Miell shares the open-source Continuous Compliance Framework (CCF), a tool for modernizing audits and controls. He explains how current manual, periodic compliance fails, especially with new regulations like DORA. He demonstrates how CCF leverages DevOps principles, agent-based architecture, and the OSCAL standard to provide continuous, centralized visibility across hybrid estates.
By Ian MiellFrom Outages to Order: Netflix’s Approach to Database Resilience with WAL
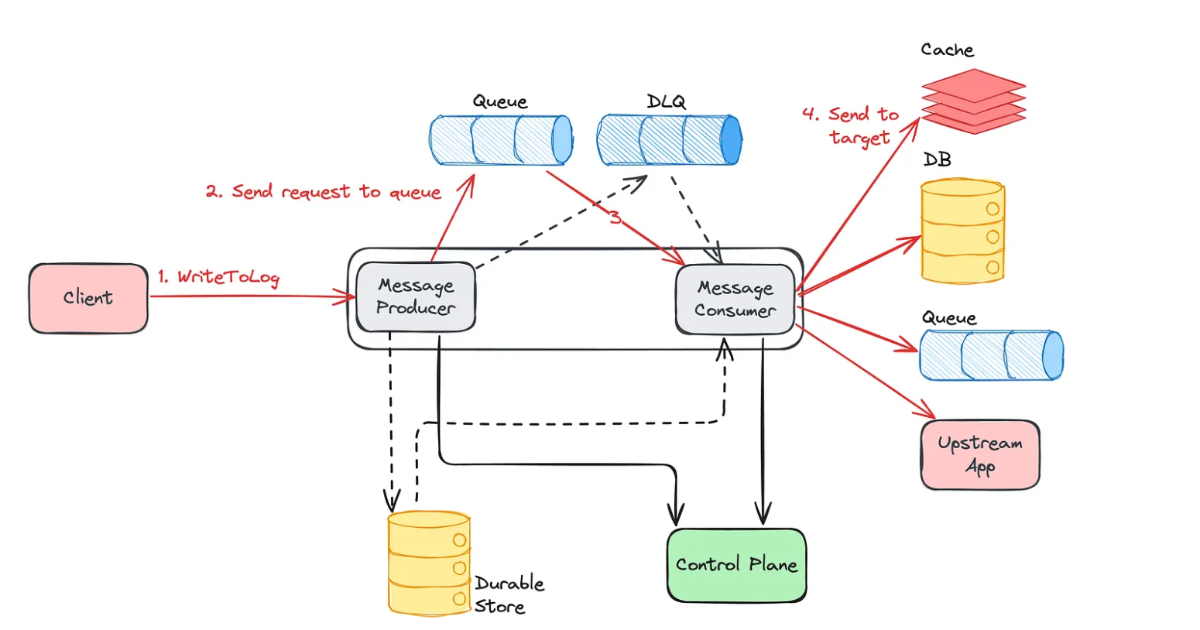
Netflix uses a Write-Ahead Log (WAL) system to improve data platform resilience, addressing data loss, replication entropy, multi-partition failures, and corruption. WAL decouples producers and consumers, leverages SQS/Kafka with dead-letter queues, and supports delay queues, cross-region replication, and multi-table mutations for high-throughput, consistent, and recoverable database operations.
By Leela Kumili
© 2025 Created by Michael Levin.
Powered by
![]()
You need to be a member of Wikipedia Place to add comments!